 ">微信
">微信# -*- coding:utf-8 -*-python爬虫豆瓣电影top250爬取
import requests
from bs4 import BeautifulSoup
import re
import time
import sys
def getHTMLText(url,k):
try:
if(k==0):kw={}
else: kw={'start':k,'filter':''}
r = requests.get(url,params=kw,headers={'User-Agent': 'Mozilla/4.0'})
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Failed!")
def getData(html):
soup = BeautifulSoup(html, "html.parser")
movieList=soup.find('ol',attrs={'class':'grid_view'})#找到第一个class属性值为grid_view的ol标签
moveInfo=[]
for movieLi in movieList.find_all('li'):#找到所有li标签
data = []
#得到电影名字
movieHd=movieLi.find('div',attrs={'class':'hd'})#找到第一个class属性值为hd的div标签
movieName=movieHd.find('span',attrs={'class':'title'}).getText()#找到第一个class属性值为title的span标签
#也可使用.string方法
data.append(movieName)
#得到电影的评分
movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText()
data.append(movieScore)
#得到电影的评价人数
movieEval=movieLi.find('div',attrs={'class':'star'})
movieEvalNum=re.findall(r'\d+',str(movieEval))[-1]
data.append(movieEvalNum)
# 得到电影的短评
movieQuote = movieLi.find('span', attrs={'class': 'inq'})
if(movieQuote):
data.append(movieQuote.getText())
else:
data.append("无")
print(outputMode.format(data[0], data[1], data[2],data[3],chr(12288)))
#将输出重定向到txt文件
output=sys.stdout
outputfile=open("moviedata.txt",'w',encoding='utf-8')
sys.stdout=outputfile
outputMode= "{0:{4}^20}\t{1:^10}\t{2:^10}\t{3:{4}<10}"
print(outputMode.format('电影名称', '评分', '评论人数', '短评', chr(12288)))
basicUrl='https://movie.douban.com/top250'
k=0
while k<=225:
html=getHTMLText(basicUrl,k)
time.sleep(2)
k+=25
getData(html)
outputfile.close()
sys.stdout=output
未经允许不得转载:萌萌Apprentissage » python爬虫爬取豆瓣电影排行榜top250

 使用python批量爬取主流搜索引擎图片
使用python批量爬取主流搜索引擎图片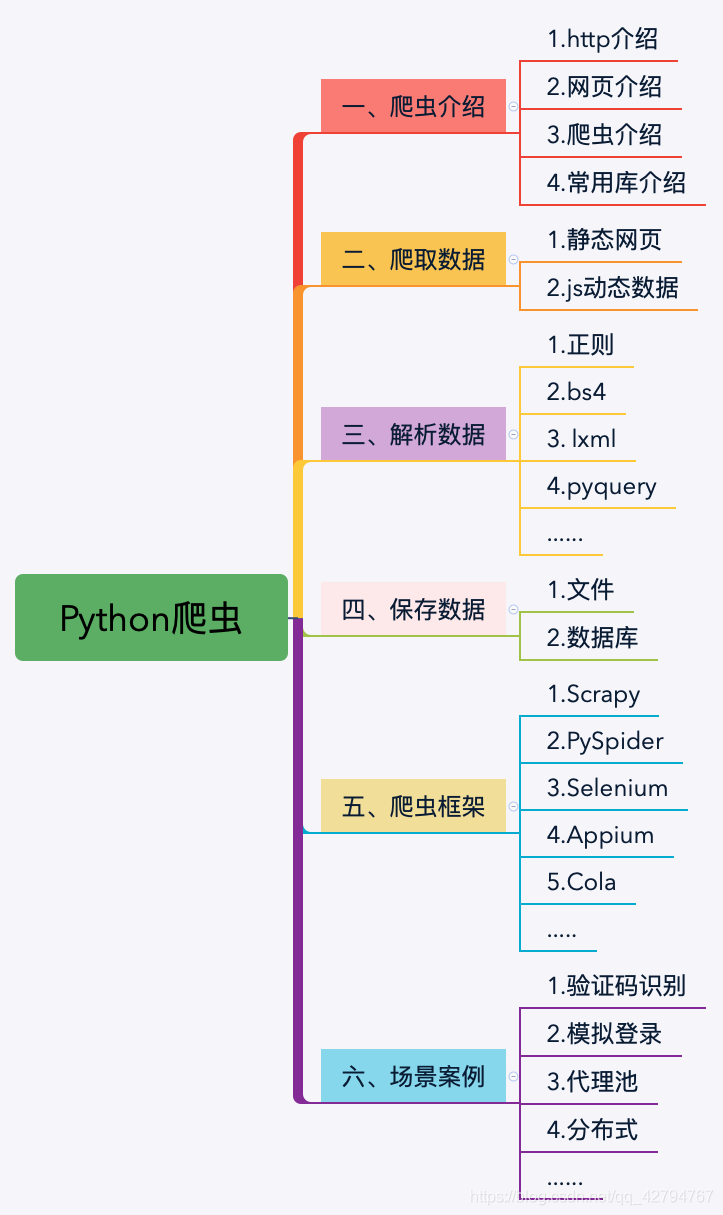 python爬虫关键词爬取百度的图片
python爬虫关键词爬取百度的图片 python库taichi太极人工智能tensoflow图形处理
python库taichi太极人工智能tensoflow图形处理 Selenium with Tor Browser using Python
Selenium with Tor Browser using Python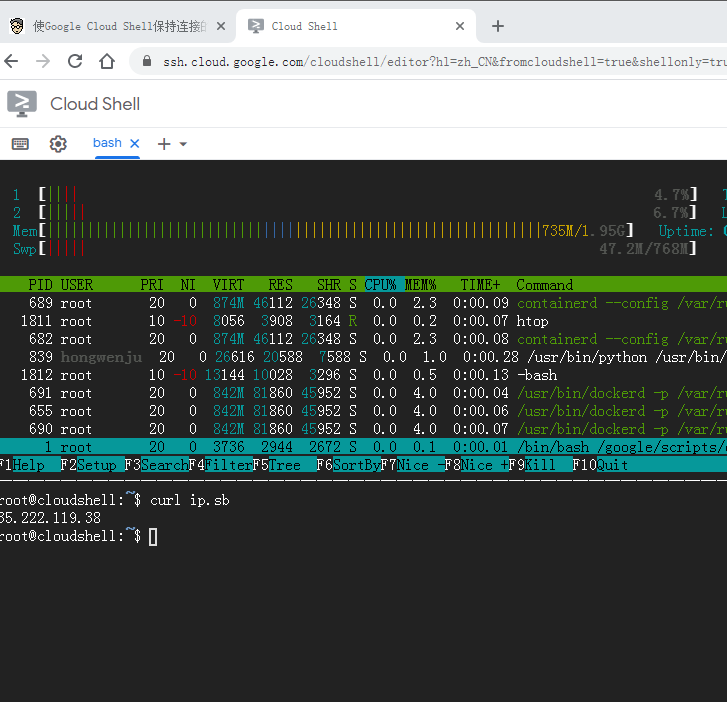 shell.cloud.google保持在线
shell.cloud.google保持在线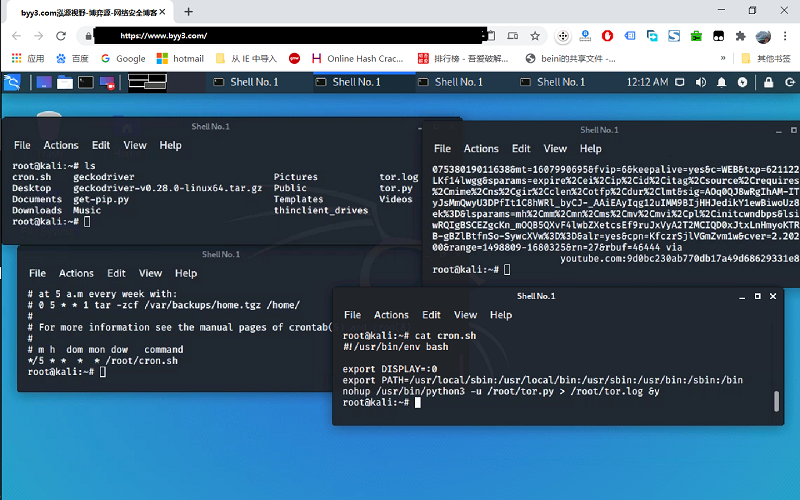 run crontab with python selenium tor browser display in linux
run crontab with python selenium tor browser display in linux
