 ">微信
">微信#python运行环境python3.9
#目标:爬取梨视频上的视频数据下载到本地
#分析网站:
# 1,数据来源 if ?{动态数据,or 静态数据}? 通过谷歌浏览器的检查判断源代码
# 2,数据抓包分析
#视频排行榜页面列表https://www.pearvideo.com/popular_loading.jsp?reqType=1&categoryId=&start=40&sort=39&mrd=0.3765578053919627(瀑布流加载方式翻页)通过检查network-XHR(popular_longing)
#结果为动态视频 https://www.pearvideo.com/video_1705502 目标视频播放网址
#视频链接存放:https://www.pearvideo.com/videoStatus.jsp?contId=1705502&mrd=0.6076594161036941 (通过network-XHR缓存地址)
#(假)视频播放地址https://video.pearvideo.com/mp4/adshort/20201105/1604657107043-15468144_adpkg-ad_hd.mp4(network-XHR-preview-videoinfo展开数据得到videourl)
#(真)视频播放地址:https://video.pearvideo.com/mp4/adshort/20201105/cont-1705502-15468144_adpkg-ad_hd.mp4(通过目标源代码Elements右键播放处选择检查源代码得到)
#流程:
# 1,url
# 2,发送请求,接受响应
# 3,解析网页
# 4,保存数据
import re
import requests
def get_url(video_id):
url = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd=0.6076594161036941'.format(video_id)
headers = {
#防盗链,确定来路
'Referer': 'https://www.pearvideo.com/video_{}'.format(video_id),
#用户代理 确定用户信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
}
response = requests.get(url,headers=headers)
# print(response.text)
html_data = response.json()
video_url = html_data['videoInfo']['videos']['srcUrl']
# print(video_url)
#正则表达式用于id 替换真url地址 cont- 构造真的链接地址
new_url = re.sub(r'\/\d{13}-',f'/cont-{video_id}-',video_url)
# print(new_url)
#存放视频地址
path = r'G:\video\\' + video_id + '.mp4' #很重要文件夹路径后面是两个\\ 不然后面出现’下面警告波浪线
resp = requests.get(new_url)
with open(path,mode='wb') as f:
f.write(resp.content) #.content用于保存二进制数据
for page in range(0,10,10):
url = 'https://www.pearvideo.com/popular_loading.jsp'
params = {
'reqType': '1',
'categoryId':'',
'start':'{}'.format(page),
'sort' : '1',
'mrd' :'0.3765578053919627',
}
response = requests.get(url,params=params)
# print(response.text)
titles = re.findall('<h2 class="popularem-title">(.*?)</h2>',response.text)
# print(titles)
num_id = re.findall('<a href="video_(\d+)" class="popularembd actplay">',response.text)
# print(num_id)
# 这里代表第几(0)个视频数(留空则默认上面1-10的视频)
get_url(num_id[0])
未经允许不得转载:萌萌Apprentissage » python实例,突破反爬,爬取梨视频并下载

 使用python批量爬取主流搜索引擎图片
使用python批量爬取主流搜索引擎图片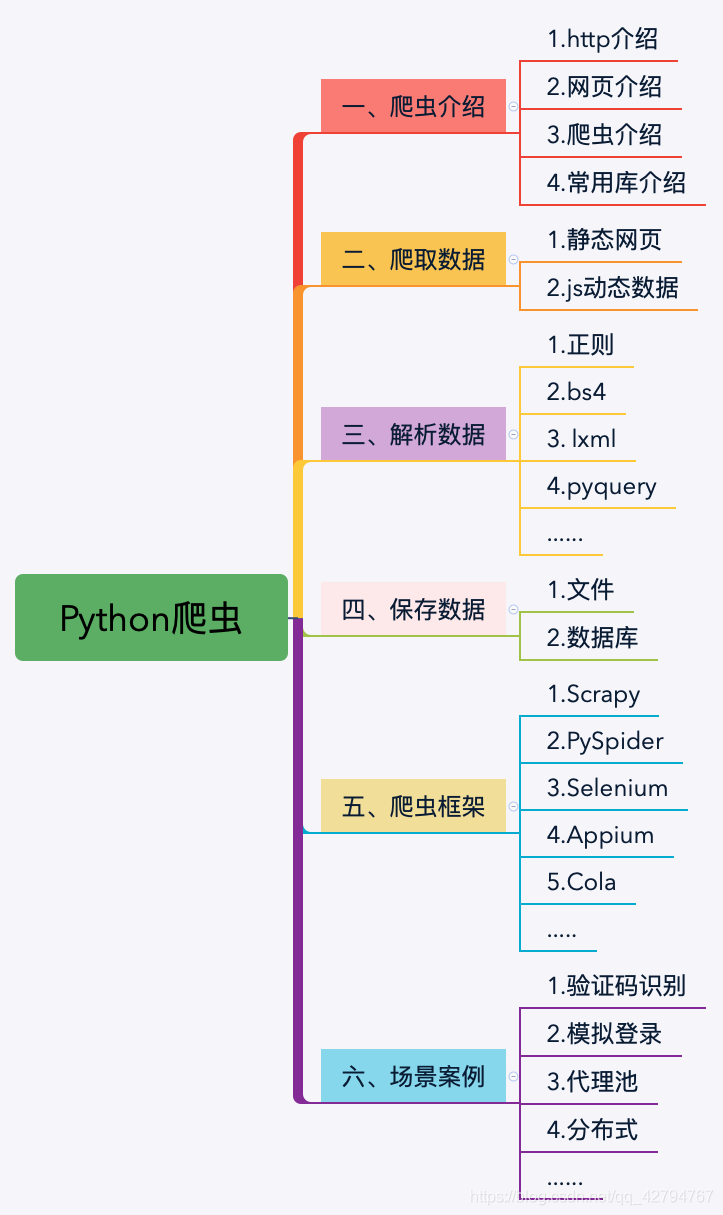 python爬虫关键词爬取百度的图片
python爬虫关键词爬取百度的图片 python库taichi太极人工智能tensoflow图形处理
python库taichi太极人工智能tensoflow图形处理 Selenium with Tor Browser using Python
Selenium with Tor Browser using Python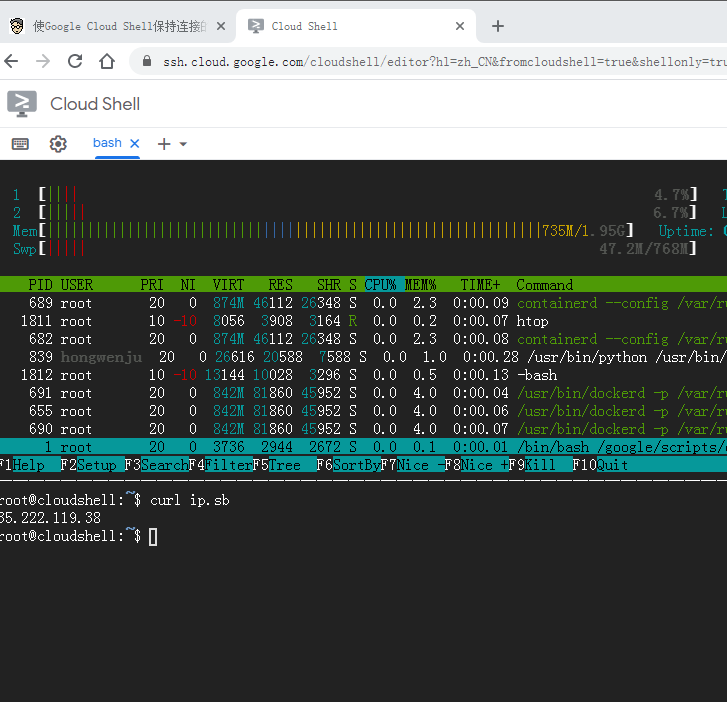 shell.cloud.google保持在线
shell.cloud.google保持在线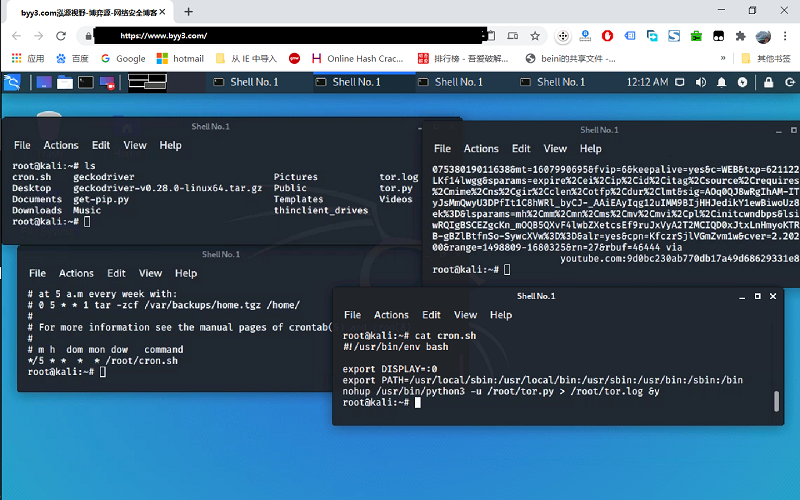 run crontab with python selenium tor browser display in linux
run crontab with python selenium tor browser display in linux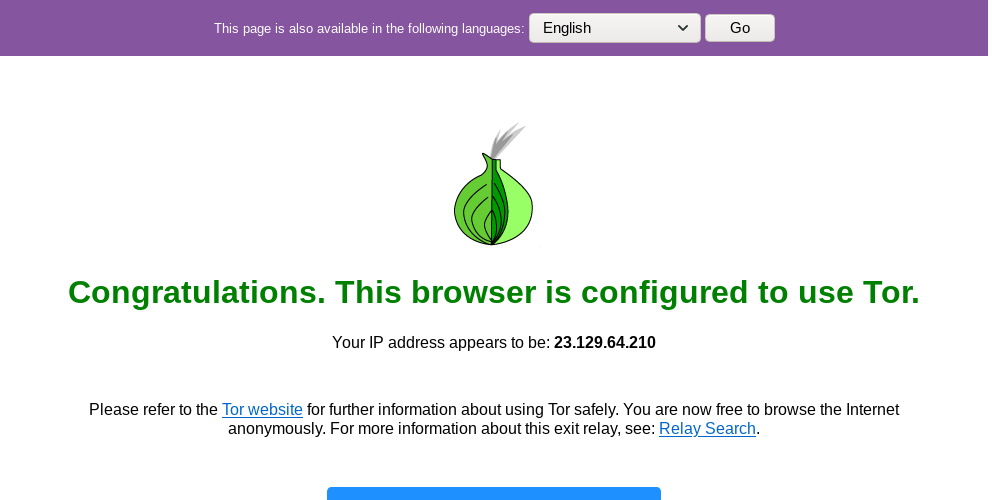 linux环境使用python调用tor浏览器随机浏览器网页
linux环境使用python调用tor浏览器随机浏览器网页
