 ">微信
">微信最近在做一个口罩识别的应用,需要很多戴口罩的人的图片作为数据训练模型,因公司没有提供数据,只能我们自己用python爬虫爬取各主流网站的戴口罩的图片,我们主要爬取了必应、360、搜狗的图片(百度的有点杂,不如这三家个),代码如下(仅供学习参考):
必应搜索
from bs4 import BeautifulSoup import urllib.request import requests import time import json import sys import re import os #爬取目标网站url CRAWL_TARGET_URL = 'https://cn.bing.com/images/async?q=%s&first=%d&count=%d&relp=%d&lostate=r&mmasync=1' #每次抓取图片数量(35是此网页每次翻页请求数量) NUMS_PER_CRAWL = 35 #抓取图片最小大小(单位字节),小于此值抛弃 MIN_IMAGE_SIZE = 102400 def get_image(url, path, count): try: u = urllib.request.urlopen(url, timeout=9) t = u.read() if sys.getsizeof(t) < MIN_IMAGE_SIZE: return -1 except Exception as e: print(url, e) return -2 #提取图片格式 frmt = url[url.rfind('.'):] p = re.compile("^\\.[a-zA-Z]+") m = p.match(frmt) frmt = m.group(0) try: if not os.path.exists(path): os.mkdir(path) f = open(os.path.join(path, str(count)+frmt), 'wb') f.write(t) f.close() except Exception as e: print(os.path.join(path, str(count)+frmt), e) return -3 return 0 def crawl_data(info, num): first = 0 count = 0 #创建一个会话 s = requests.Session() #创建文件路径 path="./"+info if not os.path.exists(path): os.mkdir(path) index=len(os.listdir(path))#文件中原有图片数 while(count < num): u = CRAWL_TARGET_URL%(info, first, NUMS_PER_CRAWL, NUMS_PER_CRAWL) #5.05s为发送超时时间,10s为接收到数据超时时间 req = s.get(url =u, timeout=(5.05, 10)) bf = BeautifulSoup(req.text, "html.parser") imgtags = bf.find_all("a", class_ = "iusc") for e in imgtags: if count == num: return False urldict = json.loads(e.get('m')) if get_image(urldict["murl"], path, index) < 0: continue print("Downloaded %d picture"%(count+1)) sys.stdout.flush() count =count+1 index=index+1 time.sleep(0.09) first = first + NUMS_PER_CRAWL time.sleep(0.9) return True if __name__ == '__main__': # 关键词,可设置为多个 key_words=['戴口罩',] # 下载的图片数量 picture_num = 500 for i in range(len(key_words)): word=key_words[i] print(word) if crawl_data(word, picture_num): i=i+1
360搜索
import json import os import requests # 路径 BASE_URL = './戴口罩' # 关键词 NAME = '戴口罩' class PictureDownload(object): def __init__(self, q=None, sn=100): self.url = 'https://m.image.so.com/j?q={}&src=srp&pn=100&sn={}&kn=0&gn=0&cn=0' self.headers = { 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1' } self.q = q self.sn = sn self.num = 0 self.total = 2 def makedir(self): if not os.path.exists(os.path.join(BASE_URL, self.q)): os.makedirs(os.path.join(BASE_URL, self.q)) def parse_url(self): response = requests.get(self.url.format(self.q, self.num), headers=self.headers) return response.content.decode() def parse_image_list(self, html_json_str): image_list = json.loads(html_json_str)['list'] total = json.loads(html_json_str)['total'] return image_list, total def save_image(self, image_list): for item in image_list: response = requests.get(item['thumb'], headers=self.headers) with open(os.path.join(BASE_URL, '%s\%s.jpg' % (self.q, item['index'])), 'wb') as f: f.write(response.content) def run(self): self.makedir() while self.num < self.total: html_json_str = self.parse_url() image_list, self.total = self.parse_image_list(html_json_str) self.save_image(image_list) self.num += 100 print(self.num) if __name__ == '__main__': xxx = PictureDownload(NAME) xxx.run()
搜狗搜索
import requests import json import urllib # 三个参数,你要获取整个图片集的名字,你要获取多少张,获取过来的放在哪里 def getSogoulmag(category,length,path): n=length cate=category # 获取的是图片所有信息 imgs=requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+ '&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n)) # 转换成为json格式 jd=json.loads(imgs.text) # all_items所有的图片 jd=jd['all_items'] imgs_t=[] for j in jd: # 通过定位bthumbUrl获取图片 imgs_t.append(j['bthumbUrl']) m=0 for img in imgs_t: # 打印某一张图片正在下载 print(str(m)+'.jpg'+'Downlod......') # 用来把远程数据下载到本地 urllib.request.urlretrieve(img,path+str(m)+'.jpg') m=m+1 print('Complete!') # 调用整个处理逻辑 # 三个参数,你要获取整个图片集的名字,你要获取多少张,获取过来的放在哪里 getSogoulmag('戴口罩',10,'./sougoutupian/')
爬取360图片的过程如图1所示:

图1 爬取360图片全过程
我们可以看到,使用 pycharm运行程序后,图片陆续开始下载,当然,有些图片是干扰数据,需要手动清理掉,相比于一张张下载,还是方便很多的。
未经允许不得转载:萌萌Apprentissage » 使用python批量爬取主流搜索引擎图片

 python爬虫关键词爬取百度的图片
python爬虫关键词爬取百度的图片 python库taichi太极人工智能tensoflow图形处理
python库taichi太极人工智能tensoflow图形处理 Selenium with Tor Browser using Python
Selenium with Tor Browser using Python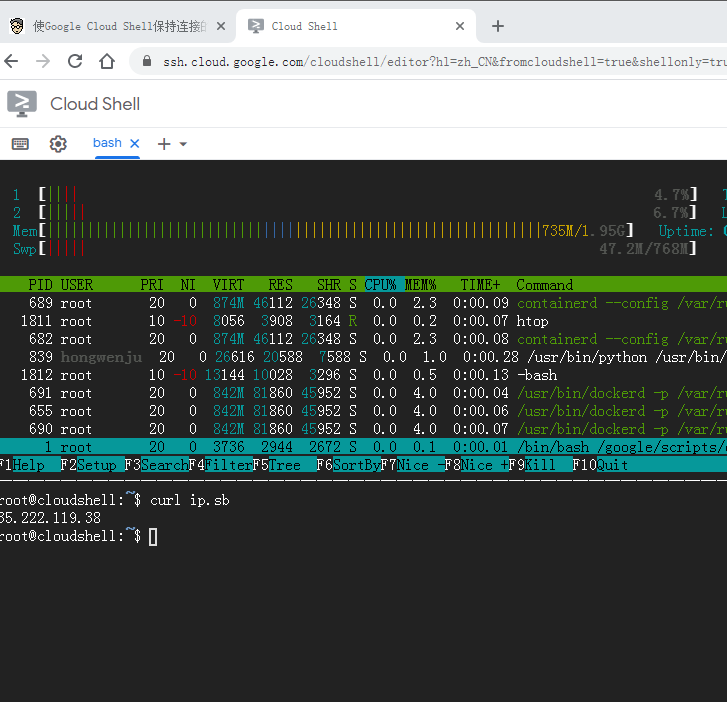 shell.cloud.google保持在线
shell.cloud.google保持在线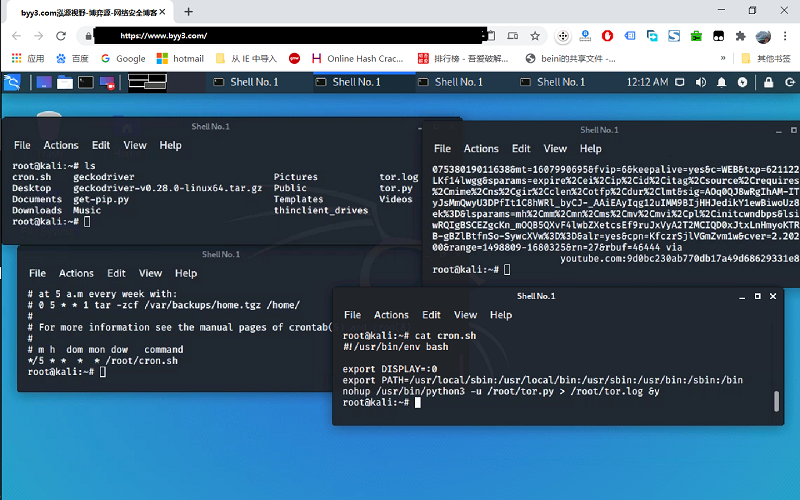 run crontab with python selenium tor browser display in linux
run crontab with python selenium tor browser display in linux
